Azure AD と AWS SSOの連携
はじめに
AWSアカウントがたくさん増えて、アカウントごとにIAMユーザーがいて、それぞれにMFAを設定して、、もう大変! となった経験はありますでしょうか。
私は今もそういった経験をしておりますが、そんなマルチアカウントのログインの助けになるのがAWS SSOです。 マイボス佐々木さんが構成の整理と説明を以下の記事でわかりやすくしてくれています。
↑の記事でもおススメの構成となっている、IdP + AWS SSOのパターンを今回は試してみたいと思います。

IdPはAzure上でマネージドで作成できる、Azure Active Directoryを使用します。 AWSと同じくクラウド環境のため、画面上からポチポチするだけでADおよびユーザーが作成できるので検証に便利です。
それではやっていきましょう。
AWS SSOの設定
SSOはOrganizationsの組織情報を使用した機能となるため、Organizationsの親アカウントで設定する必要があります。
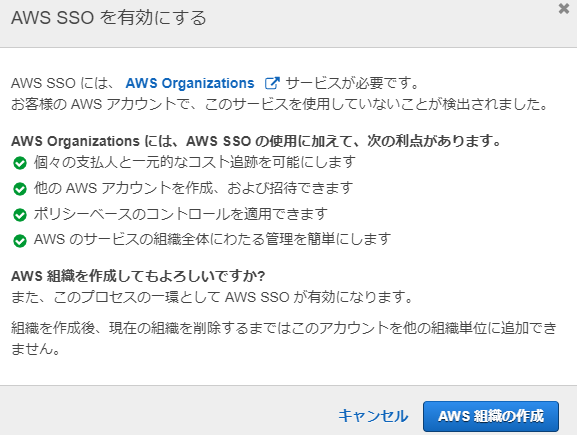
AWS SSO画面に遷移し、有効にします。

Organizationsの組織が作成されていない場合は、以下のとおり表示されます。 AWS組織の作成を押すことで、組織が自動作成されます。
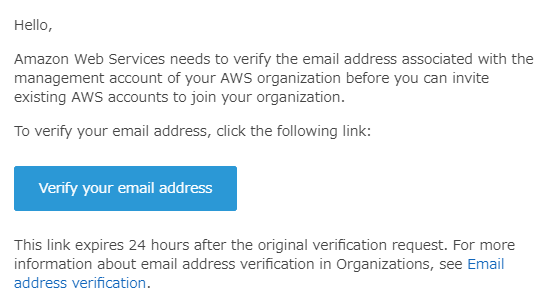
組織の作成時、メールの検証が必要となるため、アカウントのメールアドレスに届いたメールを確認して青いボタンを押しておきます。
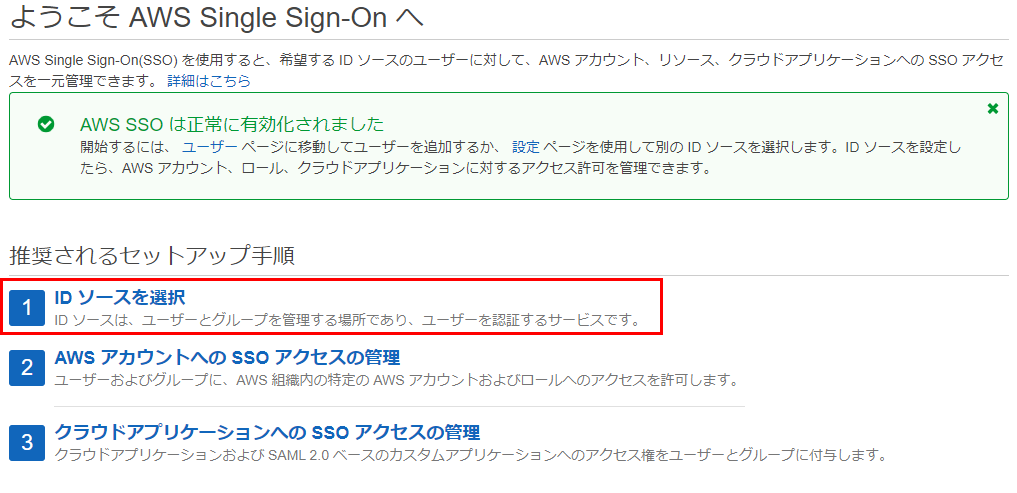
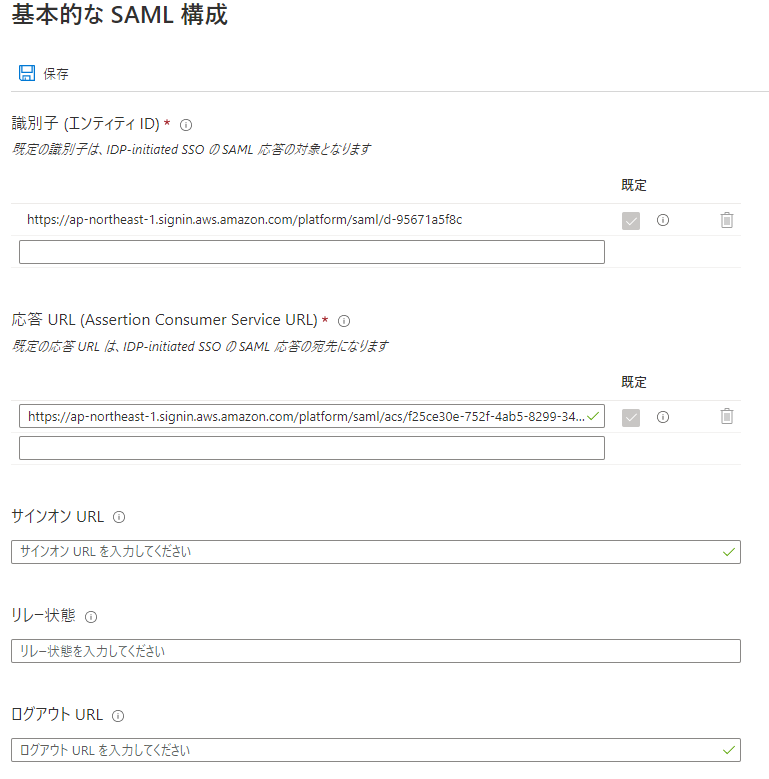
外部のAzureADをIDソースとして利用します。 IDソースを選択を押下して設定画面へすすみます。
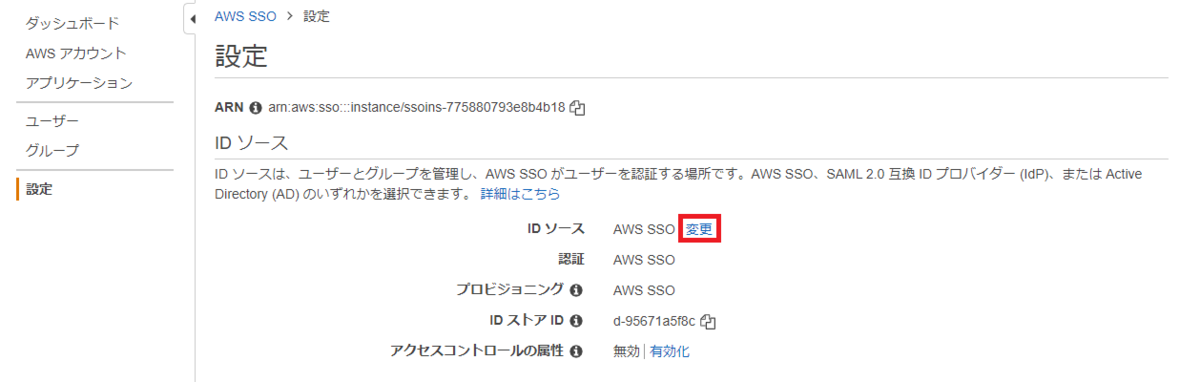
IDソースの変更を押します。
メタデータファイルをダウンロードしておきます。

Azure ADの設定
新規テナント、ユーザーの作成
Azureのテナントとは不動産のテナントと同様で、ユーザーやグループ、オブジェクトなどをひとまとまりで管理できる部屋のようなものです。Azureアカウント作成時にデフォルトで1つのテナントがあるのですが、今回は新規でSSO用の専用テナントを作成します。
Azure Active Directoryの画面へ遷移し、テナントを作成をおします。
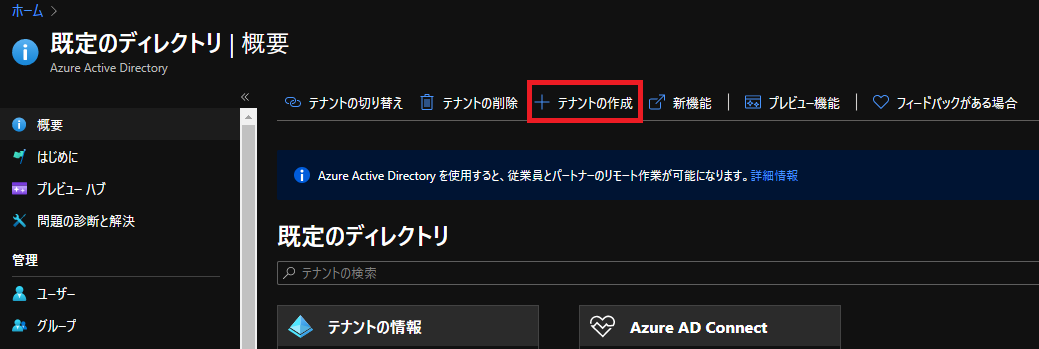
デフォルトのAzure ADでOK。
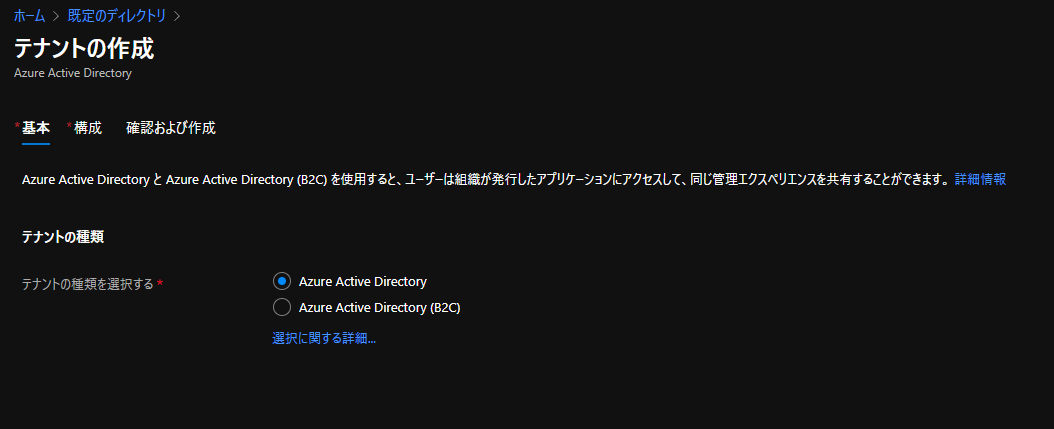
任意の組織名、ドメイン名を入力します。
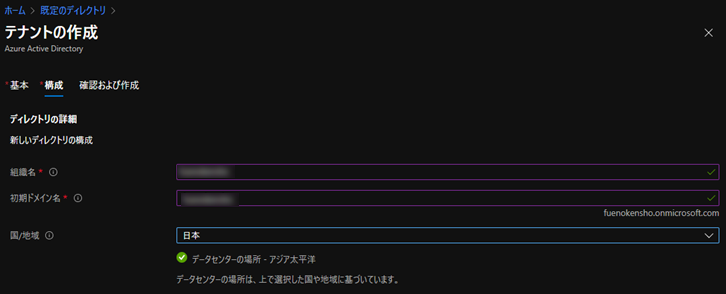
確認して作成します。
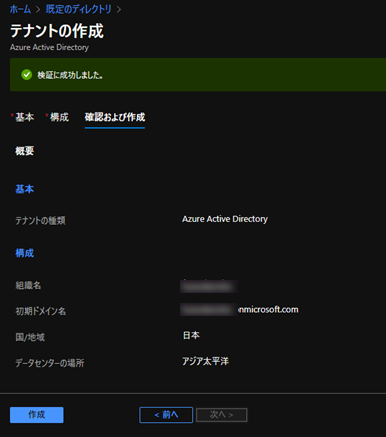
テナントの作成が完了したら、作成したテナント上で、ログイン確認用のユーザーを作成しておきます。
(もともとのテナントがダークモードONだったので色が変わりました)
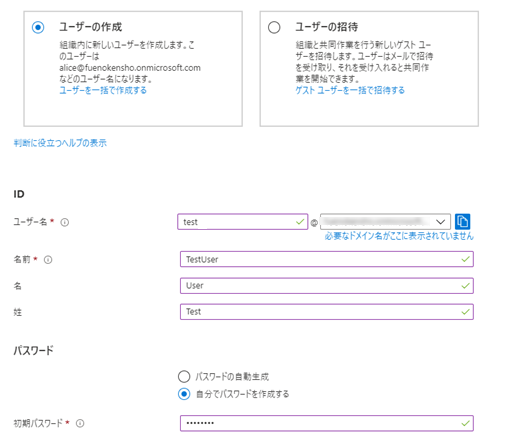
testという名前で作成しておきます。名と姓を入力しておかないとAWS側でエラーになるため注意です。
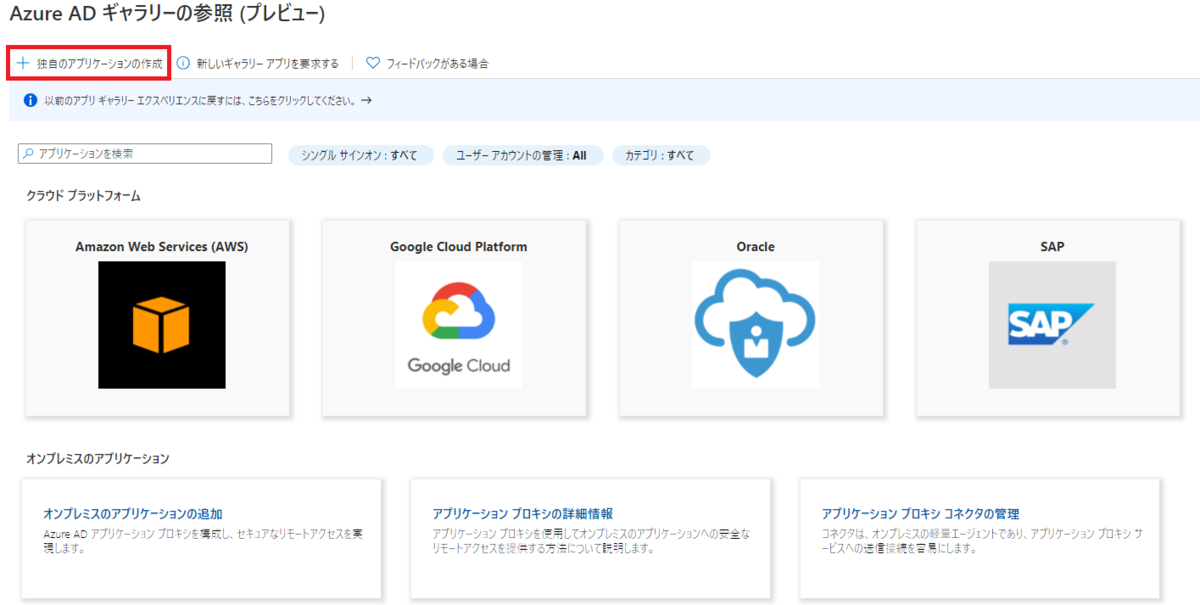
アプリケーションの作成
AWSへ連携するために、エンタープライズアプリケーションを作成します。

新しいアプリケーションを作成を選ぶと、以下の通り各種サービスが選択できます。 AWSが一番最初に大きく出てくるので押したくなりますが、今回はAWS SSOなので独自のアプリケーションを作成をおします。
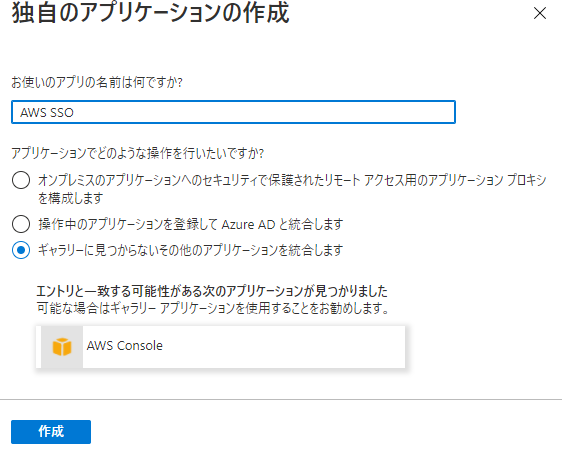
名前は任意でOKです。今回はAWS SSOとして作成します。
作成後以下のような画面になるので、シングルサインオンの設定をおします。
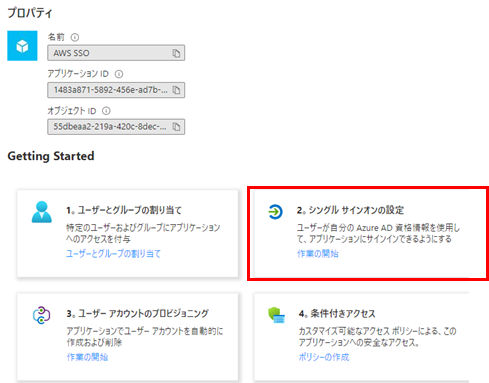
SAMLを選択

さきほどAWS SSOの画面からダウンロードしたメタデータを使うので、メタデータファイルのアップロードを選択します。
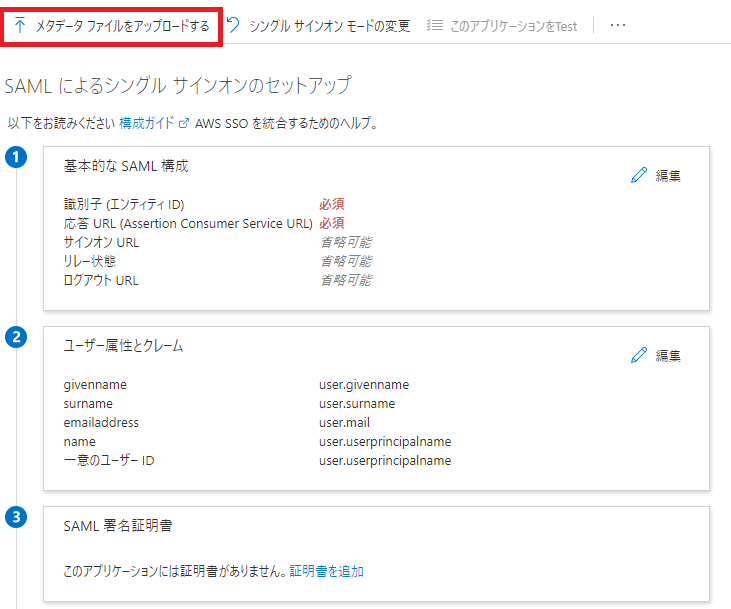

アップロードすると右側に以下の画面が表示されます。そのまま保存を押せばOKです。
Testするのか表示されますが、AWS側の設定がまだ完了していないため、ここはいいえにします。

このあとブラウザのリロードを行うと、以下のようにSAML署名証明書にメタデータのダウンロードリンクが表示されるので、そこからダウンロードします。

AWS SSOの設定(つづき)
AWS側に戻ります。
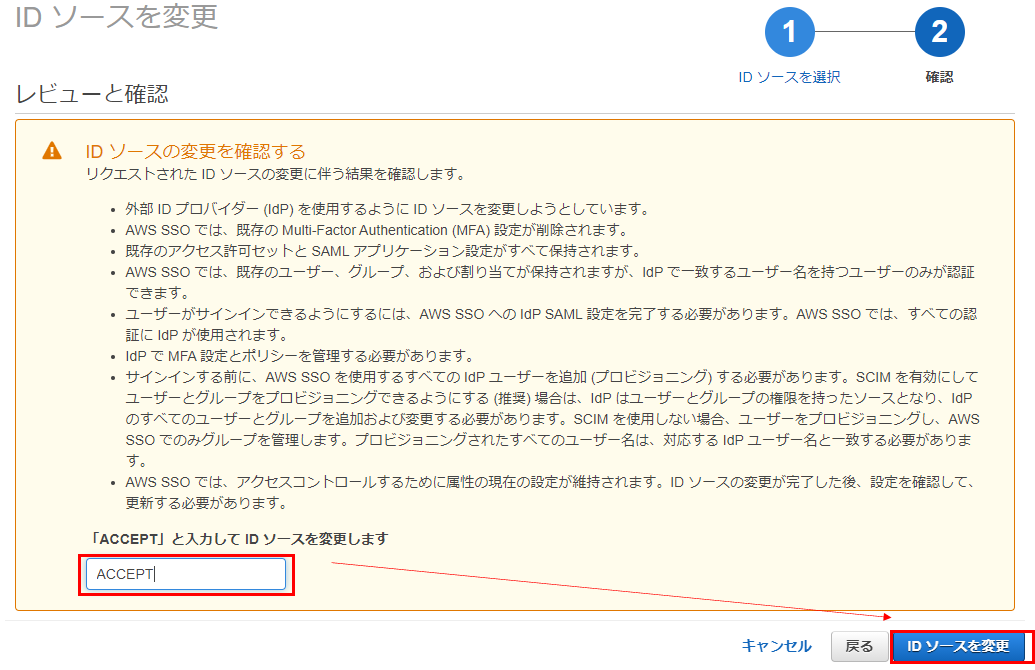
IDプロバイダーのメタデータのところから、Azure側でダウンロードしたメタデータファイルをアップロードします。

ACCEPTと入力し、IDソースを変更します。
完了!

今回はADのユーザーが自動的にAWS側にも連携されるよう、自動プロビジョニングを有効化しておきます。
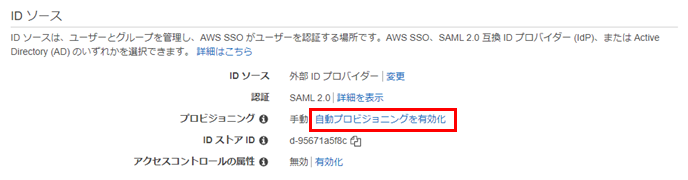
SCIMエンドポイントとアクセストークンの情報はメモしておきます。
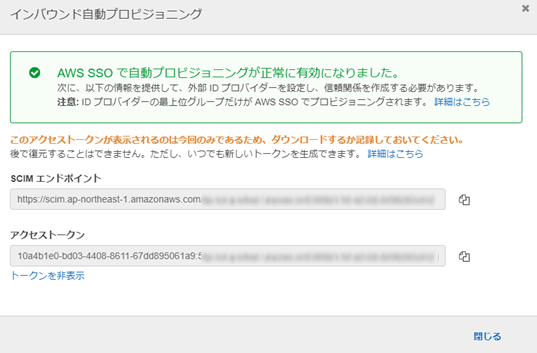
Azure 側プロビジョニング設定
またAzureに戻ります(行ったり来たり・・)
さきほど作成したアプリケーションからプロビジョニングの設定をしていきます。
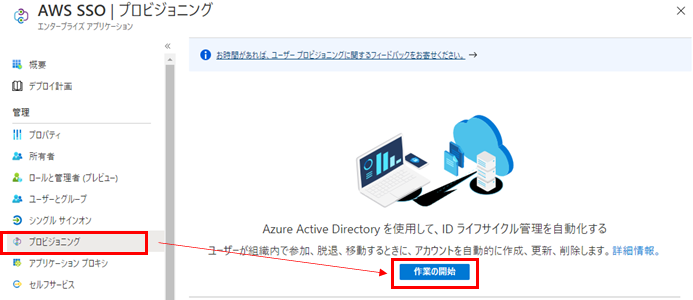
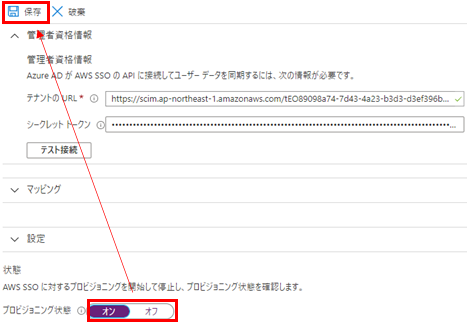
プロビジョニングモードを自動に変更して、さきほどメモしたURLとトークン情報を入力し、テスト接続を行います。無事接続できると右上に成功の旨が表示されます。
その後、左上の保存を押します。
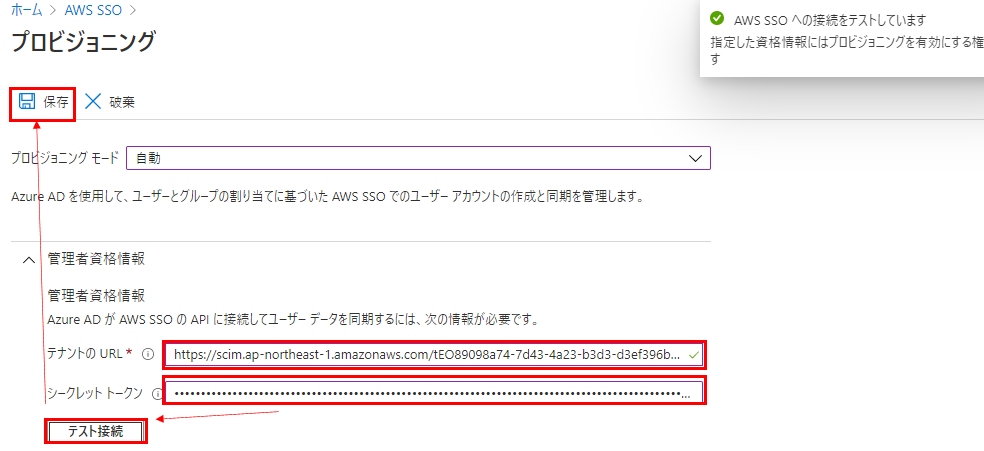
一度保存すると下部のプロビジョニング状態を変更できるので、オンにして保存します。
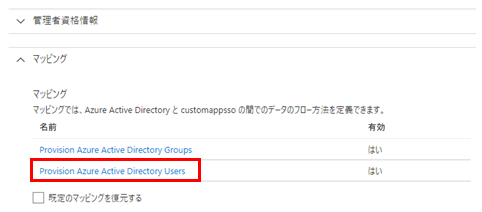
ユーザー属性のマッピング情報を変更します。
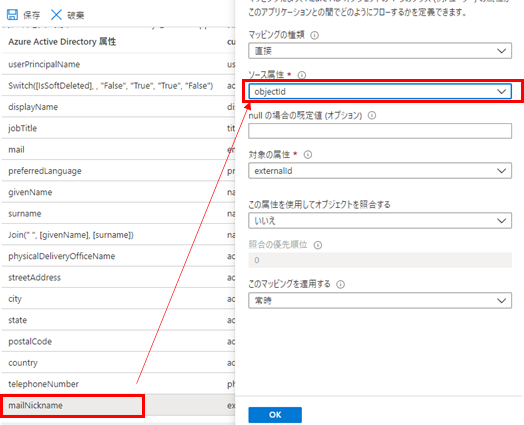
「mobile」と「facsimileTelephoneNumber」を削除します。

「mailNickname」を「objectId」に変更します。2つの削除と1つの変更が終わったら左上の保存を押します。
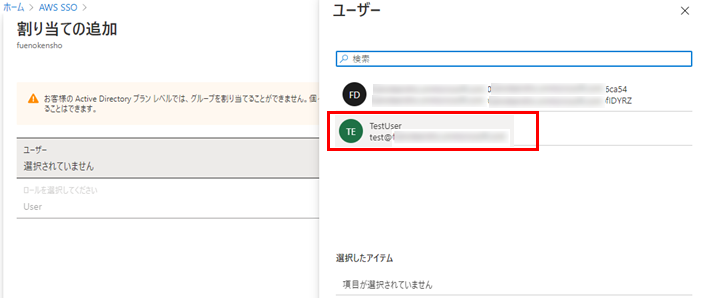
エンタープライズアプリケーションのページに戻り、ユーザーを追加します。
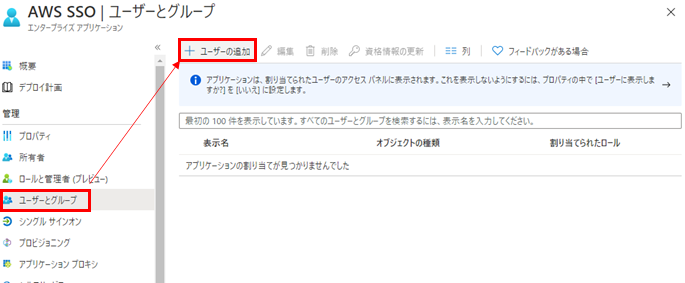
先ほどADで作成したtestユーザーを追加して割り当てます。
※本来の運用を考えると、グループ単位で割り当てたほうが良いでしょう。今回は検証用途のためユーザー単独で割り当てます。
プロビジョニングの実行間隔は40分になっているため、手動で再開して追加したユーザーを反映させます。

しばらくするとプロビジョニングが完了してユーザー1と表示されます。

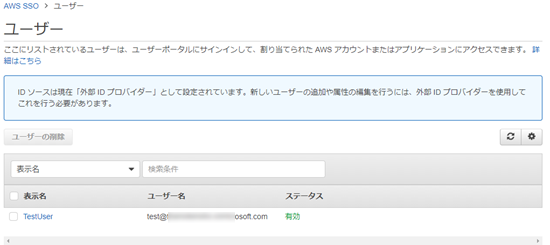
AWSのSSO画面にもユーザーが追加されています。
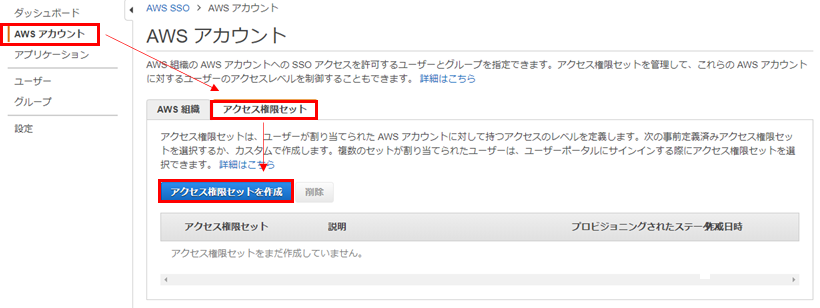
アクセス権限セット、対象AWSアカウントの決定
ログインするAWSアカウントのユーザーに付与する権限(IAMポリシー)を決定します。
アクセス権限セット
まずはアクセス権限セットの作成からです。
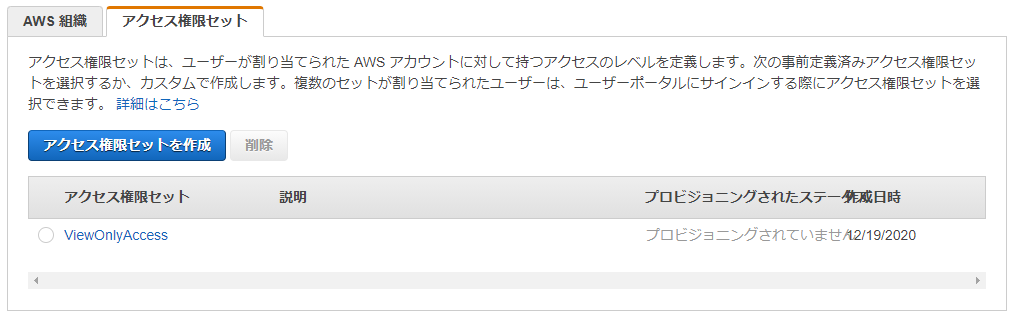
今回は検証用途のためAWS側で職務単位で用意されている職務機能ポリシーを使用します。
※本番運用時は、必要な権限を決めて最低限の権限となるように付与しましょう。

閲覧権限のみ与えるViewOnlyAccessを使用します。

タグは特に設定せず、内容確認して作成します。

できました。
対象AWSアカウントの選択と割り当て
次はログインするAWSアカウントを選んでいきます。
Organizations配下に2アカウントあるため2つ共選んでユーザーを割り当てます。
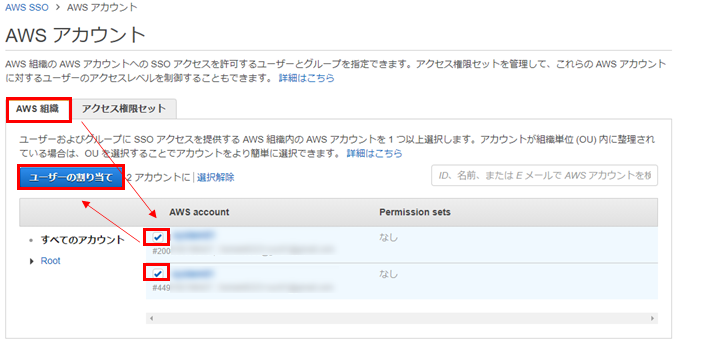
プロビジョニングされたTestUserを選択します。

先ほど作成したアクセス権限セットを作成して完了します。
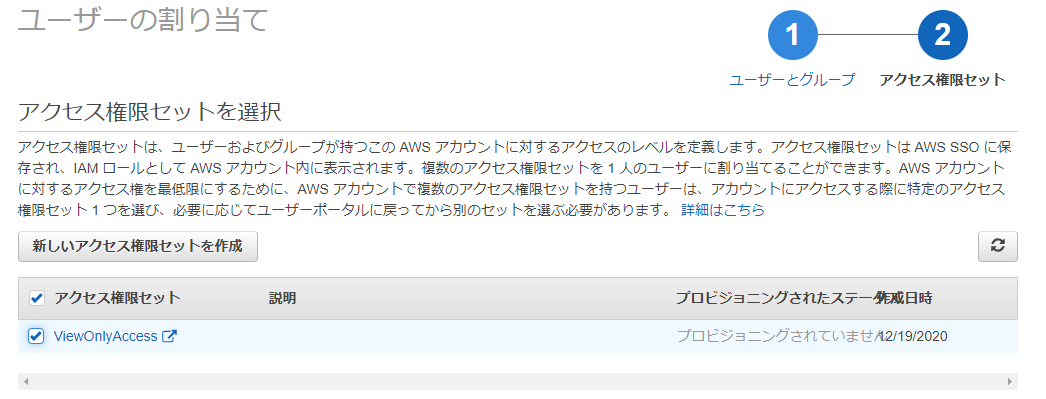
完了!
ログイン確認
設定がすべて終わったので、SSOのTOPに表示されているデフォルトのポータルURLへアクセスしてログインしてみます。

作成したAzure ADのユーザー名、パスワードを入力します。

AWS Account(2)と表示されています!クリックすると一覧でアカウントが一覧で出るのでログインしたい方を選択します。
今回はマネジメントコンソールで入ります。CLI用のキーも表示できますね。
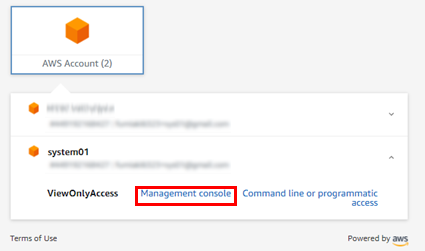
ログインできました!まっさらな状態のアカウントなのでリソースは特にない状態ですが・・。
検証は以上です。
CLIやMFAなどまだまだ試したいことはありますが、今回の記事はAzure ADでユーザーを作成してSSOと連携するところを主目的として書いていますので、ここまでとしておきます。
まとめ
ただ試してみたかっただけですw SSOが便利で重要なことは知っていたのですが、やはり自分で試してみないとわからないという主義なので、実際に触ってみました。 触ってみて改めてですが、以下のポイントが良いですね。
- ID/パスワードの管理がAWS外で一元管理できる。元々業務で使用しているIDがあればそれも流用できる
- アクセス権限セットを使用して、アカウント単位の権限ではなく、必要な権限セットを複数のアカウントに適用できる
- CLIもイケる
AWS SSOの管理がOrganizationsの親アカウント限定なので、これがOU単位であったり、もう少し細かい単位で制御できると最高かと思います。今後に期待です。
これから作ろうと思っている方何かの参考になれば幸いです。
re:Invent 2020 サービスアップデート 2週目(12/7~12/11)のまとめ
社内勉強会でしゃべったネタの一部なのですが、特に隠しておく情報でもないため、ブログに書いておこうと思います。 先週発表されてAWSのアップデートを、個人的にまとめて社内で紹介しました。 深さはあまりなく各発表の内容をざっくり書いています。
本日開催されたAWSさん公式のBlackBeltのほうが詳しい気がしますが、セルフメモ的な意味もこめて書いておきます・・
Compute
ECR cross region replication
コンテナイメージのリージョン間コピーが可能に。アカウント間コピーも可能
EC2に新たなネットワークメトリクス追加
新たに5個追加。帯域上限を超えたIN/OUTパケット数、コネクション上限を超えたパケット数、 DNSやメタデータなどのlinklocalへの上限を超えたパケット数、PPSの上限超えパケット数。
Network
VPC Reachability Analyzer
AWSサービス間のネットワーク経路を可視化できるサービス。画面上で通過するENIやSGが一目で見れるため、ネットワークが繋がらない場合に役立つ。1分析あたり$0.10
Developer tools
Amplify CLIがFargateへのコンテナデプロイへ対応
ソースコードを用意して、amplify init、configure、add、pushの数回のコマンドを実行するだけで、Fargateのサービスを公開できる。パイプラインも自動作成される
CodeGuru Profilerのメモリおよびヒープメモリ対応
CPU、レイテンシーベースだったのがメモリも対応。ヒープメモリも対象
Security
AWS Audit Manager
監査を簡略化するためのサービス。GDPR、HIPPA、PCI DSSなど主要なコンプライアンスに対応 AWSアカウント内のリソース状況を既存のサービスを使用して取得する。エビデンスを自動収集し、 コンプライアンス標準に合わせた言葉も使用される。監査レポートの出力も可能。マルチアカウントにも対応
Analytics
Amazon Redshift ML
SQLコマンドで学習モデルの作成、学習、デプロイが可能。 CREATE MODEL文でモデルが学習、デプロイされる。TARGETでラベルのカラムを指定する。 その後SELECT文で予測結果を取得可能。裏ではSageMaker(autopilotベース)が動き、アルゴリズムは自動選定
Amazon Redshift Automatic Table Optimization
クエリの状況を監視し、機械学習を使用してソートキーなどを自動選定、データの再配置も実施する
Amazon Redshift federated queryがRDS(MySQL)をサポート
PostgreSQLだけでなくMySQLも追加
Amazon Redshift native console integration with partners
パートナー企業とのやり取りがやりやすく
Amazon Redshift が JSON と semi-structured dataのサポート
半構造化データやJSONもOKになった
Amazon Redshift data sharing
Redshiftクラスター間でデータを共有するサービス
Amazon Redshift RA3.xlplus node
小さいノードができた。これまでは4xlと16xl
Amazon Neptune ML
グラフDBのNeptuneでもRedshift ML同様の仕組みで機械学習が使用可能に 不正検知やレコメンデーションなどのユースケースで使用可能
Amazon EMR Studio
EMR用のIDE。SageMakerでも使われているJupyter notebooksが使用されている。 処理コードの開発がやりやすくなる
Amazon EMR on Amazon EKS
EKS(Kubernetes)上でEMRのデータ処理を実行可能に
QuickSightがElasticsearchをサポート
データソースとしてElasticSearchの指定が可能に
ML/AI
Amazon HealthLake
多種多様な医療データをAWS上に集約し、機械学習を使用して標準化、分析が可能。HIPPAにも対応
Amazon Lookout for Metrics
CloudWatch Anomaly Detectionの他サービス対応版。数値データの異常なふるまいを機械学習を使用して検知 CW、S3、RDS、Redshiftに加え、外部のSaaSにも対応(Salesforce, Google Analyticsなど) SNS経由で通知
Amazon Forecast Weather Index
天気予報
Amazon SageMaker Edge Manager
エッジデバイス上にデプロイされた学習モデルを管理、監視するためのサービス
Amazon SageMaker Clarify
学習データの偏りを検知するサービス。 たとえば画像の年齢判定のモデルを学習する場合に、データが特定の年代に偏ってないかなど
Deep Profiling for Amazon SageMaker Debugger
昨年発表されたDebuggerの新機能。ハードウェアリソースの分析や処理の稼働状況を分析できる
Amazon SageMaker JumpStart
目的に合わせて、学習済みのさまざまな既存のモデルを選択してデプロイ可能 不正検知や数値予測、自然言語処理や画像認識などさまざまなモデルあり そのままデプロイもできるが、既存の学習モデルを*ファインチューニングして、自分のモデルも開発可能。 たとえば一般的な画像分類のモデルから商品分類のモデルを学習してデプロイすることが可能 ※「ファインチューニング」既存のモデル全体を再調整して新たなモデルを学習すること。転移学習は既存の出力に追加学習
Amazon Kendra incremental learning
検索結果に応じて、継続的に増分のデータを使用した学習が可能
Amazon Kendora のcustom synonymsサポート
ユーザ独自の特定の用語を登録可能
Amazon Kendra の Google Drive connector対応
Google Driveをデータソースとしてサポート
さいごに
一番アップデートの多かった1週目ではなく2週目ピンポイントのまとめとなりました。 先週1週間でどんな感じでアップデートがあったのか、全体感はみれるかなと思います。
MLキーノートがあったこともあり、ML/AI、Analytics系のアップデートが多かったですね。
re:Invent2020セッションレポート :(EMB023) Amazon Aurora Serverless v2: Instant scaling for demanding workloads
概要
2020 re:Inventで新しく発表された、Amazon Aurora Serverless v2のセッションです。もともとAurora Serverlessは機能としてありましたが、今回パワーアップしてv2としてリリースされました。
セッション内容
Auroraの概要
通常の(サーバーレスじゃない)Auroraの概要です。ここらへんはBlackBeltや公式ドキュメントも(特に日本の方は)わかりやすいと思います。
AuroraはAWSがクラウド環境用に開発した独自のリレーショナルデータベースサービスで、MySQLとPostgreSQLに互換性があります。通常のRDSよりもクラウドに特化した機能が多く備わっています。独自となっていますが、接続するアプリケーションから見ると従来のMySQLやPostgreSQLと同様になりますので、特別アプリケーションの変更は不要です。

- コンピュート機能とストレージ機能は分離されていて、データは3AZに分散されている

- ストレージは分離されているため、Writer(書き込み)またはReader(読み込み)ノードにアタッチするという形でノードを生成
- Writerは1ノード、Reader(リードレプリカ)は最大15個作成可能です。指定のReaderでカスタムリードエンドポイントの作成も可能
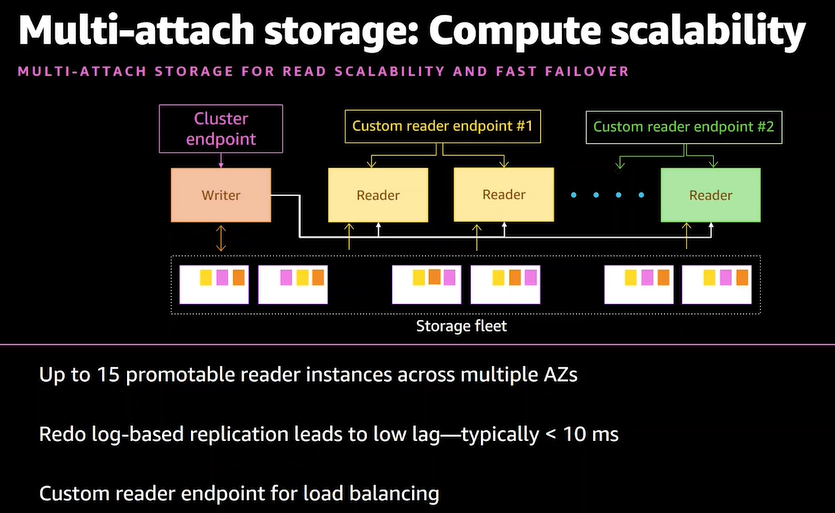
- 「クラスター」という単位でAuroraを設計、構築していく
- アプリケーションの内容がデータベースのIOスループットやレイテンシの要件に影響する
- マルチAZ等可用性の設計も行う
- ストレージの拡張やフェイルオーバーやAWS側で自動実行される
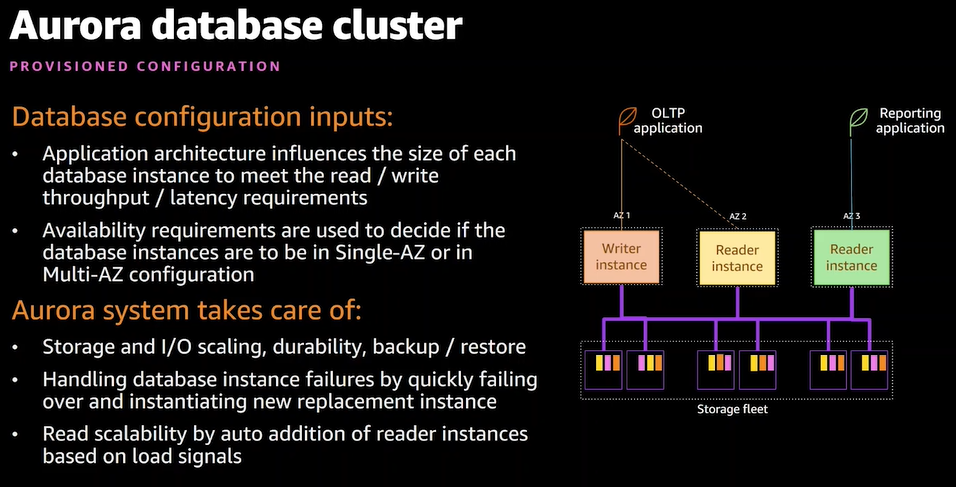
- DBのキャパシティ管理は難しい
- 3つの例を紹介、スパイキー(たまに高い)、不規則(開発など)、一定の傾向があるもの
- ピーク時に合わせて用意すると料金が高くなる
- ピークよりも低く設定するとユーザー影響が出る
- 自前でモニター、キャパシティ管理は大変
- そこでAurora Serverless!!

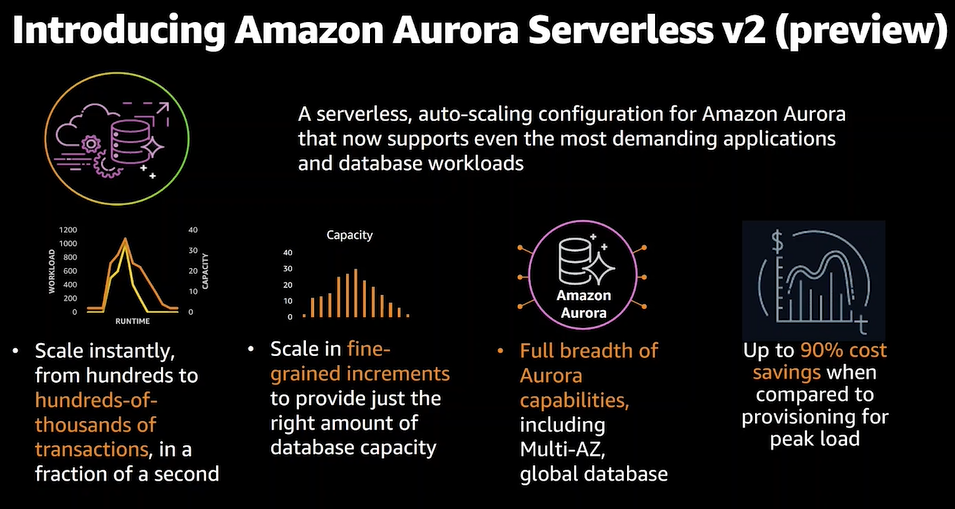
Aurora Serverless v2
- キャパシティをオートスケールしてくれる Serveless v2
- 素早くスケールするので急なアクセス増にも耐えられる
- きめ細かく的確にキャパシティを設定してくれる
- 通常のAuroraの機能もフルで使用できる。マルチAZやグローバルDBなど
- 最大90%のコスト削減
- 読み書き(Read-Write)のスケーリング
- 最初は特にノードはなく、アプリからアクセスがあると、Router fleetという部分がそれを処理し、Writerを起動する
- 起動の単位はAurora Capacity Unit(ACU)と言う
- アクセス数、クエリ数が多くなるとACUを自動で増やしていく
- 最低キャパシティを指定して、常時稼働させておくことも可能。初回接続時のインパクトを抑える

- 読み込み(Read-Only)のスケーリング
- Write同様にアクセスに応じて自動スケールする
- 読み込み専用のアクセスに応じてスケール
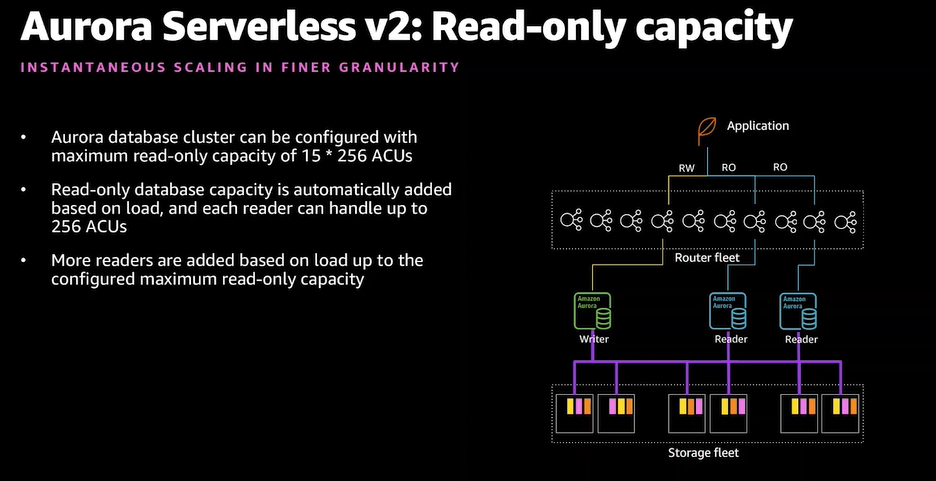
- 通常のAuroraとMixも可能
- この例ではReaderのみServerless v2

デモ
※デモは動画のほうが見やすいと思います。気になる方は是非直接セッション動画をご覧ください
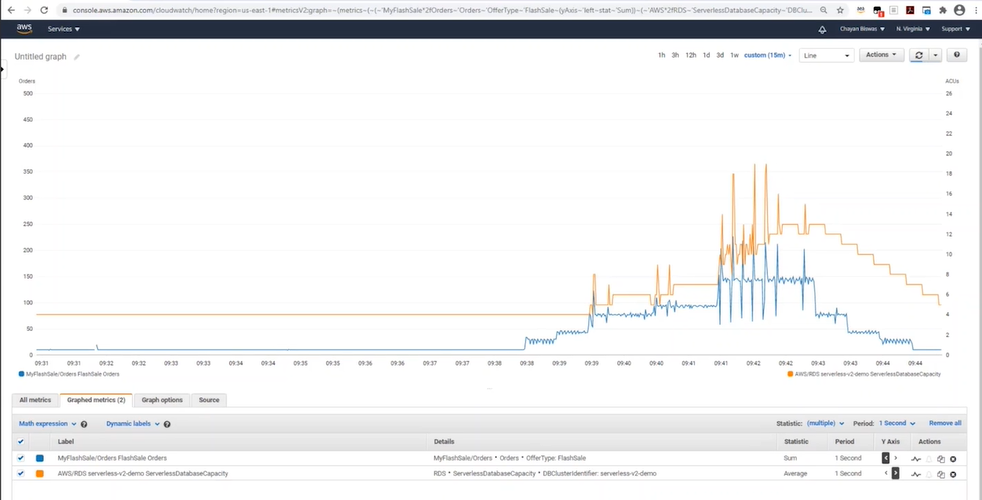
- CloudWatchメトリクスの画面。オンラインストアを例とし、青がオーダー数でオレンジがAuroraのキャパシティ
- スクリプト処理でSQLを継続実行
- スケールダウンはスケールアップよりも緩やかに行われる。バックグラウンドプロセスの動きも見ながら、影響がないように
セッションまとめ(re:Cap)
- サーバーレスなオートスケーリングAurora
- 本番環境もOK
- 数千トランザクション/秒にも耐えられる
- 必要なリソースだけ用意する、安い

感想
高機能すぎて、本当にここまでキレイに動いてくれるのかという感じですね。まだプレビュー段階ですので、今後に期待です。 このセッションを見る前は、通常のAuroraと同様に裏でノード(インスタンス)が稼働してそれをAWSが自動管理してくれるのかと思っていましたが、Lambdaのような小さなVMが稼働し、それをスケールアウト/インしてきめ細やかなキャパシティ管理を実現しているということでうね。驚きました。
RDSのノードタイプの決定や、そのサイズ、レプリカ個数の管理は難しい、というか構築したら基本はそのまま稼働させるという考えが多かったので、そこを動的に変えてくれるなら任せてみたいですね。使用前の金額見積が難しい部分はありますが、基本は安くなると思うので期待です。
Chatbotと時間限定IAMポリシーを使用した本番接続運用を考える
こんにちは。上野と申します。
Japan APN Ambassador Advent Calendar 2020 10日目のエントリです。AWSさんに挟まれた日程で記事を書いております。ほかの方の記事も、おもしろいものばかりですので是非読んでみてください。
Ambassadorって何?というかたは下記の記事を読んでもらえるとわかると思います。
私は2020年にAmbassadorとして選んでいただきました。資格取得や登壇、執筆などが評価され、選出いただいたと考えています。
本エントリの内容について
私は技術的なネタを書きます。
コロナウィルスの影響で在宅勤務が増えるなか、みなさま本番システムのアクセスはどう管理していますでしょうか。 オフィス内に本番接続ルームを用意して、そこからアクセスするという運用をされている方も多いと思います。
ただ、今後もコロナの状況が続くとなると、中々オフィスに出向くのは厳しいかもしれません。そこで私からは本番アクセスの一例として、Chatbotと時間限定IAMポリシーを使用したアクセス運用を紹介したいと思います。
実際に運用で使っているわけではなく、私の1アイディアですので参考として読んでいただけると幸いです。
使用するサービスについての前知識
Chatbot
Chatbotは、SlackやAmazon ChimeのチャットツールとAWSを連携するサービスです。チャットでメッセージ送信をトリガーにLambda関数を実行できるため、今回はそれを使用します。
なお、Chatbotを準備してLambda関数を実行するまでの内容は以下記事で解説しています。
時間限定IAMポリシー
IAMポリシーには、ConditionにDateLessThanを指定することで、時間限定のAWSアクセスを付与できます。 今回はこれを使用して一時的なアクセスをユーザーに付与します。
「IAMポリシーの例」
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "*", "Resource": "*", "Condition": { "DateGreaterThan": {"aws:CurrentTime": "2020-04-01T00:00:00Z"}, "DateLessThan": {"aws:CurrentTime": "2020-06-30T23:59:59Z"} } } ] }
参考: AWS: 日付と時刻に基づいてアクセスを許可する - AWS Identity and Access Management
運用方法(利用時)の流れ
技術的な点は一旦置いておいて、どのような流れで一時アクセスを付与するのか流れで説明します。
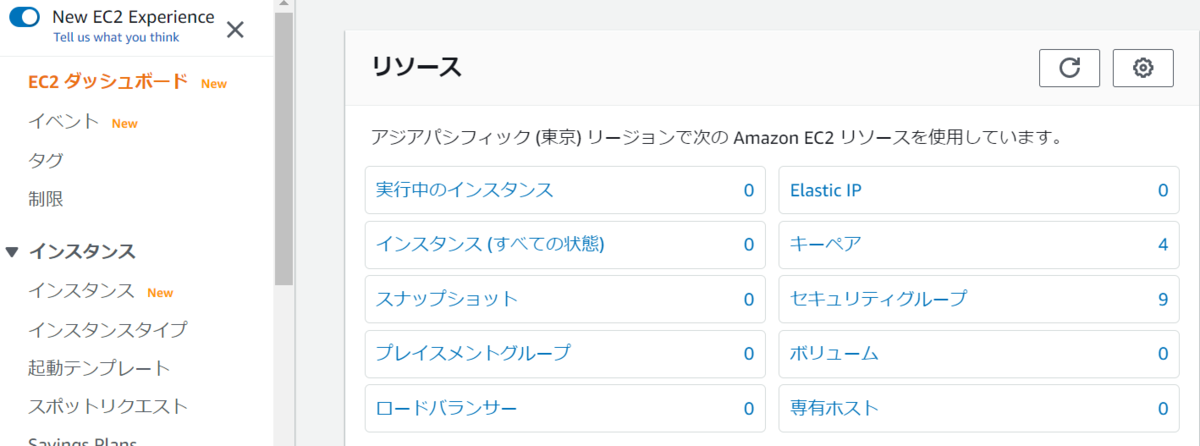
1.デフォルトの状態=何もできない
デフォルト状態では、IAMポリシーを空にしておき、IAMユーザーはログインのみできる状態にしておきます。

この状態でログインしてEC2の画面を表示すると、以下のとおりAPIエラーとなり各種情報が表示されません。 本番の運用状況にもよりますが、例えばデフォルトRead権限はつけておくというポリシーもありかと思います。

2.Slack経由でIAMユーザーに権限を付与する。
IAMユーザーが本番アクセス(AWSへログイン)が必要になったとします。
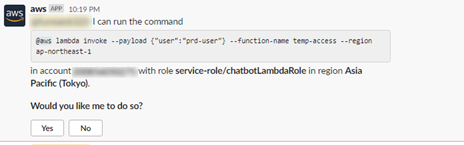
管理者がSlack上に↓のメッセージを実行することで、指定したユーザーに権限が付与されます。
ここではユーザー名をprd-userとします。--payloadオプションでIAMユーザー名を指定しています。
@aws lambda invoke temp-access --payload {"user":"prd-user"}
すると以下の通りChatbotが実行するか質問してくるので、Yesを押します。
Lambdaが実行されます。「End time is・・」に記載されている時刻は、 IAMユーザーのアクセスが不可となる時間です。(UTCで表示されてます)
※時刻の設定やレスポンスはLambda内でもろもろ実装
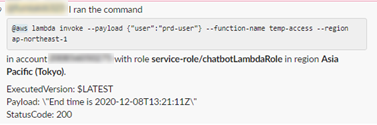
この時点でアクセス権限が付与されました。

3.IAMユーザーログイン
アクセス権限が付与されたので、アクセスしてみます。
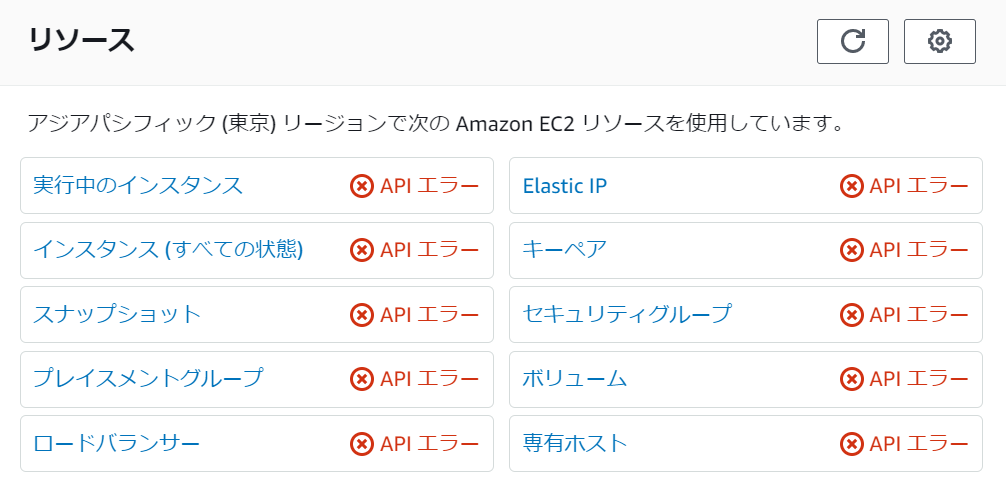
以下のように、先ほどAPIエラーとなっていた各数値の情報が表示されました。 これでアクセスが可能になったことがわかります。
今回はIAMユーザーにAdministratorAccess同様(全許可)のポリシーを時間限定で付与しています。 実運用では、本番運用に必要な権限のみ許可するほうが良いでしょう。
4.指定時間経過後
指定した時間が経過すると、以下のようにまた情報が表示されなくなります。特に再ログインは無しで、画面遷移していると急にエラーになります。
そのため設定する利用時間は慎重に設定する必要があります。また、ChatbotからLambdaを再実行すれば期間延長可能です。
運用方法はここまでです。
技術情報の補足
ソースコードは以下githubに置いています。 CloudFormationテンプレート(CreateTempIAMPolicy.yml)をデプロイすれば、Lambda関数が作成されます。 Chatbot経由のLambda実行は繰り返しになりますがこちらの記事を参考にしてください。
アーキテクチャは以下の通りです。 LambdaがIAMポリシーを付与するだけという、割とシンプルなつくりです。

その他いくつか実装面の補足情報を書いておきます。
- 利用可能な時間は、Lambda関数の環境変数で設定しています。CloudFormationテンプレートのデフォルトは180で、単位は分です。(3時間)
- IAMポリシーはIAMユーザーにインラインポリシーとして設定しています。通常ポリシーを一元管理にするために、管理ポリシーを付与してそれをIAMグループに付与するのが一般的ですが、今回は指定したユーザーのみに付与するためインラインにしました。
- 指定時間が経過しても、インラインポリシー自体は残り続けます。ただし時間切れ状態です。再度Lambda関数が実行されると、ポリシーが新しい時間で上書きされます。
実運用上での考慮事項
実際の本番運用で使う場合は、この実装だけでは足りず、追加で考慮も必要になるかと思います。 いくつか検討事項として出てきそうなところを書いてみます。
IAMポリシーについて
運用方法の流れでも書いたとおり、例では許可するActionとResourceを*(=全許可)で指定しているため、実際の運用では本番運用で必要な権限のみ指定して許可する必要があります。 また、IAMポリシーではIP制限をかけたり、MFAを強制させることもできますので、そういった追加のセキュリティポリシーを追加するとよりセキュアなアクセスが実現できます。
本番持ち出しについて
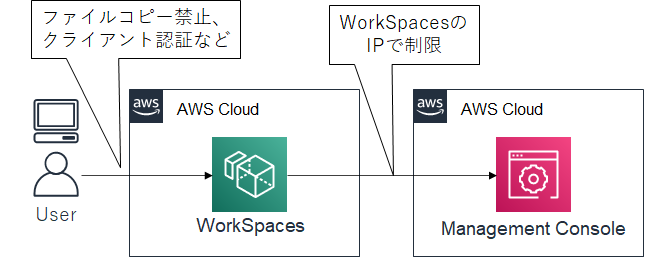
IP制限など、特定の端末にアクセスを絞らない場合は、データの端末への持ち出しが気になるところです。以下は1つの例ですが、WorkSpacesを本番アクセス仮想端末として使用することで、ファイルの端末への書き出しを防ぐことができます。
WorkSpacesへのログインは、クライアント証明書ベースの認証もできるので、証明書が入った端末のみアクセス可能といった制御もできますね。
VPC内へのアクセスについて
VPC内にEC2を多く配置していると、EC2にSSHでログインすることもあるかと思います。
私としては、サーバーに直接SSHアクセスするのではなく、Systems ManagerのSession Managerを使用してサーバーアクセスするのが良いと思います。こうすることでサーバアクセスの認証もIAMで一元管理できるからです。操作ログも取得も可能です。Session Managerの使い方はこちらに書いています。
Chatbotの利用について
今回、Slackの特定のチャンネルからChatbotを実行できるようにしているのですが、このチャンネル内のユーザーであれば誰でもLambda関数が実行可能となります。そのため、管理者のみのプライベートチャンネルにしたほうが良いです。
Lambda側で呼び出したSlackユーザー情報が取れれば、ユーザーに応じて処理実行有無を制御できるのですが、現状Slackユーザー情報は取得できないようです。
まとめ
すいません、なんだか長くなってしまった気がします。
本番運用されている方、アクセス方法に悩まれている方も多いかと思いますので、何かの参考になれば幸いです。
今回ご紹介したのは1つの手段です。アクセス手段を作ることは目的ではなく、本番上の情報を守ることが本来の目的かと思いますので、どういったら守れるのか、そういった観点でアクセス方法も考えていきたいですね。
ありがとうございました、明日のアドベントカレンダーもお楽しみに!!
re:Invent2020セッションレポート :(BLD207) Hands-off: Automating continuous delivery pipelines at Amazon
概要
Amazonにおける継続的デプロイ(CD)自動化の事例紹介です。 この内容はThe Amazon Builders' Libraryの記事にも掲載されており、基本的にはそれと同じ内容です。 ブログのほうが詳細な部分もある気がしますが、セッションでは人の説明を聞くことでよりわかりやすい部分もあったかなという印象です。
内容
スピーカーのClareさんもAmazonに来る前はVery manual(手動)だとおっしゃっていましたw
- AWSサービスのCDパイプライン例、多くのStageあり

Balance safety and speed deployments
- 本番リリースは安全に行いたい、でもできるだけ早く顧客へ届けたい。バランスが重要
- スピードを重視すると顧客影響が大きくなる、ゆっくりデプロイすること(例えば1顧客ごと)でリスクは下げられる
- Amazonのアプローチは、まずは小さい範囲でデプロイ、その後広げる(多くの範囲にデプロイ)

- パイプラインはマイクロサービス単位で用意、細かく分けることでサービス全体への影響を下げる

- ただしプロダクションデプロイメントでは影響が出ることも多い、そこでOne-Boxを追加

- One-Box
- One-BoxはいわゆるEC2やコンテナを1個ということ
- 新アプリケーションのインスタンスを1つ用意して、例えば10%という小さい割合で流す

- 徐々に新アプリインスタンスを増やしていく、最終的に全部入れ替え

- 更にリスクを低減するためRegion単位でOne-box、デプロイステージを用意
- ただしこれでも最初のRegionはリスクがあるかもしれない

- Regionから更にAZ単位に分解

- AZ単位で全部やってたら遅いよね(最初のスピードとリスクの話も含め)

- スピードUPのためWaveという概念を投入
- Waveで並行デプロイを実現
- 最初の2つは小さいスコープ(1Region)、うまくいったら対象リージョンを増やして並行に

- 実際の開発現場ではさまざまな機能追加があるため、色々なデプロイが入り混じる。1つ目のパイプライン実行中に次が来るなど
- Waveではステージごとに独立したデプロイを実現しているため、各ステージでバージョンが異なっても問題ない
- これにより多数のデプロイを実現している

- Waveの詳細、1Waveの中身
- ステージを並行にしているだけで、各ステージあたりのスコープは小さい
- 1Waveの中で異なるバージョンの混在も可能

Roll back automatically
- Amazonに入る前は、リリース後メトリクスグラフ(レスポンスタイム)とにらめっこしていた
- これは異常なのか?など考えながら見ていた
- Amazonではそれはやらない、hands-off、自動化
- 開発者がメトリクスを見るのではなく、パイプラインに監視させる


- パイプラインは多くのメトリクスを見ている
- リージョン単位、AZ単位、One-Box単位でもメトリクスを見ている

- フロント、Backend、DBなど各レイヤーが相互に影響することもあるため、それぞれ監視する

- リリース後、しばらくしてから異常になることもある
- Bake Timeという期間を設けており、リリース後、Baketime中も監視を継続する
- Bake Time中にSpike(異常)が発生したら自動ロールバックする。次のステージにも進まない

- 1つのリージョンで障害が発生すると、on-callエンジニアがその後どうするのか判断する
- すべてロールバックすることも、そのまま他のリージョンは進めて対象リージョンだけ修正することも可能

- Amazonでは互換性を大事にしているため、旧フォーマットでの処理ができるか確認する
- Prepare(準備フェーズ)で、新フォーマットと旧フォーマットを処理して問題ないことを確認する、エクササイズ段階で書き込みは旧フォーマットベース
- 問題ないことを確認できたら、Activateを行い、書き込みを新フォーマットベースにする
- (必要であれば)旧フォーマットの処理ロジックをコードから削除する
- すべてのデプロイが互換性を持ったデプロイができるわけではない

Automate pre-production testing
- Build段階ではユニットテスト、静的コード解析を行う。IaCではLintersを使用
- AlphaステージでFunctional tests、コンポーネントの単体テスト
- BetaステージでEnd-to-end tests、システム全体で処理が問題ないか確認する
- フロント、バックエンド、DBがあればその3層全てを見る
- Gammaステージでは Production環境に近いテストを実施

- 下位互換性を確認するために、Zetaテストを設定することもある

セッションまとめ
- Hands-off デプロイの主要な戦略はそこまで多くない、それらをどう組み合わせてパイプラインとして構築するか考えている
- バランスとスピードを取るためにOne-box、AZ、リージョン、Waveという単位でリリース
- メトリクスベースのアラームを用意して自動ロールバック、リリース後のBaketimeも用意
- 本番リリース前にひととおりのテストをパイプライン実行する
- 最初に見せたパイプラインは一見複雑(テキストも小さい)であるが、説明したコアな戦略を理解すれば、そこまで複雑ではない。処理が組み合わさっているだけ
- builders-libraryも見てね

感想
リリース処理、監視、ロールバック、テストなど自動化レベルの最高峰かなと感じました。 私としてもこういったリリース処理やテスト等はパイプラインに任せたほうが楽になるし、かつ品質も良くなると考えているため、真似できるところは実装してみたいなと思いました。
特にGammaステージの本番同等のテストはなかなか難しいかもしれませんが・・
一方で、ソースコードは徹底的に人の目でレビューをしているところ、on-callエンジニアがいること(親近感)もあり、サービス品質に直結するところはやはり人による対応が必要なんだなと感じました。
また、小さな単位でリリースを行っているとのことでしたが、例えば大規模リリースやキャンペーンなどで全リージョン(もしくは1リージョン)で同タイミングリリースが必要な場合は、また別の工夫点があるのかなと気になりました。
パイプラインの本質を知れたような気がして、とても良かったです。
re:Invent2020セッションレポート:(EMB019) Deep dive on AWS Glue Elastic Views
概要
2020 re:Inventで新たに登場した AWS Glue Elastic Viewsの紹介セッションです。 AWS Glueは既存のサービスで、データ分析用のデータETL(抽出、変換、読み込み )処理や対象データスキーマ管理に使用されます。
今回はGlueの新機能としてElastic Viewsが出ました
Why AWS Glue Elastic Views?
- 従来の仕組みはアプリケーション+データベースの2層構成
- オンラインショップを例とすると、オーダー情報や個人情報を元に、不正検知やレコメンデーション等色々な処理が必要になる。
- 1つのDBではこれら色々な処理をするのは難しい

- AWSでは目的ベースでDBサービスが用意されている
- オンラインショップの場合もやりたい処理内容に合わせてDBを選択する


ショッピングカタログを例
- 100万人ユーザー、100万RPS
おそらくこういった例ではDynamoDBを使用する

- もしこのアプリケーション(+DB)が稼働中で、テキスト検索がしたいという要件が出たらどうするか?
- テキスト検索に特化したElasticSearchを用意して、DynamoDBから読み込む
- コピー処理には複雑なコードが必要で、エラーのリトライ管理、パイプラインの管理もしなければいけない→大変

- そこでGlue Elastic Viewsの登場!

What are Glue Elastic Views
- Elastic Viewsとは
(文字スライド多めだったのでキャプチャ割愛)
Ease of use
- 簡単に使えます
- ここではDynamoDB→ElasticSearchの例
1.作業の流れ
- テーブル、View、Materialize view

2.テーブルの作成(DynamoDB)

3.テーブルのActivate
- 最初はinactivateなので手動でActivateする
- Activateを押すと、テーブル情報が見れる

4.Viewの作成


5.マテリアライズドViewの作成
- ターゲットのElasticSearchと名前を指定

6.データのMapping
- 自動的に推奨のタイプが表示される、手動変更も可能

手順はここまで
Programmability and correctness (プログラムのしやすさと正しさ)
- PartiQLの仕組みを使用して、さまざまなAWSデータサービスに接続ができる

- documentという形でデータ情報の定義ができる

- ここで最初の質問に戻り、どうやったらDynamoDBのデータをテキスト検索できるようになるか?
- Elastic Views を使用

- Viewの作成例 *(細かなSQLの紹介がありつつ、)以下の要にCREATE VIEW文を使って変換が可能

- データの互換性、変換例(DynamoDB→Redshift)

- Mapping View
- 値の変換も可能(色付のところ)

- DynamoDBのデータは柔軟性があるので、想定外のデータが入ることもある。(バイナリのような)
- 例外データとしてS3などに別出しできる

- Violation Views
- 例外データを抽出するためのView
- この例では通常データはRedshift、例外をS3へ


- コードで書きたい場合はSQLを書き込むこともできる

Re:cap
- 2021年に向けてサポートするデータソースおよびターゲットの追加を多く予定している
- フィードバックください!
感想
データのETL処理はこれまで、Glueで実現するならGlueジョブを用意して、パイプライン用意して、実行間隔などを決めてなど色々とやることがありました。 もちろんジョブコードの開発も必要。
ジョブ作成に関しては、GUIベースでよりわかりやすく開発ができるGlue Studioが今年?に発表されていました。 Glue Studioは、下記クラメソさんの記事がわかりやすいと思います。
それに対しGlue Elastic Viewsでは、ジョブだけでなく処理実行の管理までマネージドになり、より利用者の開発範囲が小さくなった機能のように見えました。 全てのユースケースで使えるかはまだ微妙なところですが、マッチするのであれば積極的に使っていきたいですね。
まだプレビュー段階なのでわからないことは多いですが、一般公開されたらまた見ていきたいです。
re:Invent2020セッションレポート :(EMB008)AWS Proton: Automating infrastructure provisioning & code deployments
概要
2020 re:Inventで新たに登場した AWS Protonの紹介セッションです。 機能が多そうで、Keynoteだけでは中々中身まで理解するのが難しかったので本セッションを見ました。
アライさんがものすごくわかりやすい記事を書いてくれているので、それを見るだけでも理解が深まると思います。 こちらも是非。
内容
課題点、背景
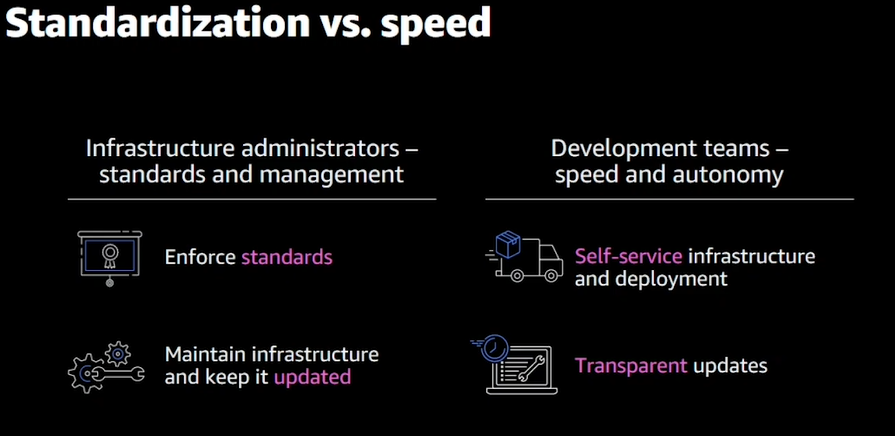
- マイクロサービスの例
- Developerは使いやすい、コードフォーカス

- 一見シンプルであるが、実はシンプルじゃない
- マイクロサービスにするとコンポーネントが増える
- Pipelineも必要、設定も環境ごとに必要
- Monitoringの設定も必要

- インフラは標準化して管理しやすくしたい
- Developer(開発チーム)は開発を早くして自動化したい
- それぞれアップデートも必要
- アーキテクチャーが育ってくるとサービスも増えて複雑になる

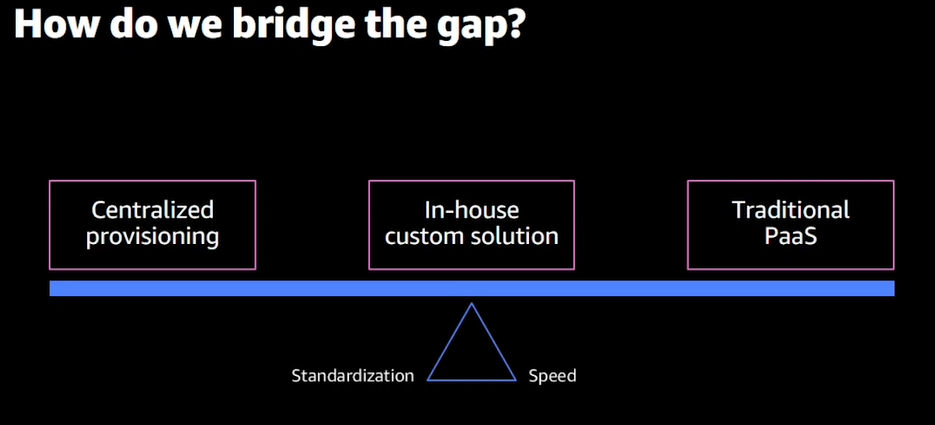
- 集中管理(左側):一元管理になるが変更時が面倒。Developerから問合せを受けて検討、変更する等のフロー
- 従来のPaas(右側):DeveloperはPaasにデプロイするので開発しやすい、一方でコンプライアンスやセキュリティが守られているか等の管理面で不安がある。
- セルフ(In-house)管理(真ん中):集中管理とDeveloperの間が取れてGood!ただし、このカスタムソリューションを自分たちで管理していく必要がある。バージョン管理なども大変
- そこでProtonの登場!!
Protonとは
- インフラ担当はインフラテンプレートをアップロード(パイプラインやモニタリングも)
- アプリ担当はアプリケーションをデプロイ

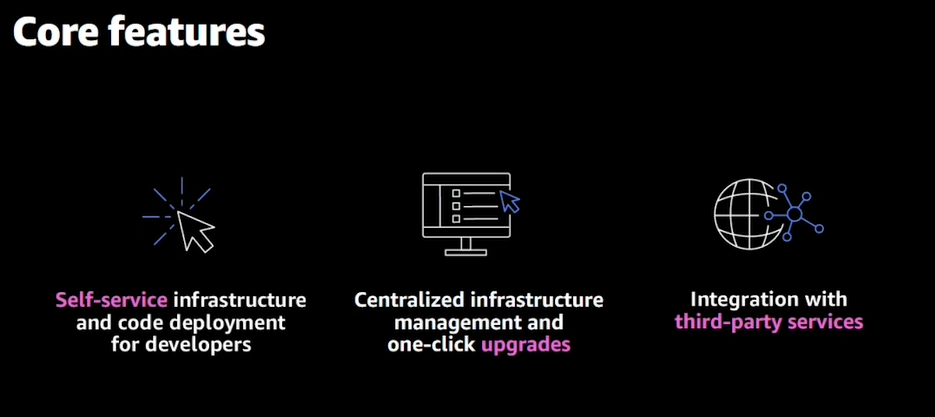
- 主要な機能
- セルフサービスなインフラおよびコード管理
- インフラ管理をワンクリックで集中管理できる
- サードパーティの組み込みも可能(TerraformやJenkinsやモニタリングツールも予定)

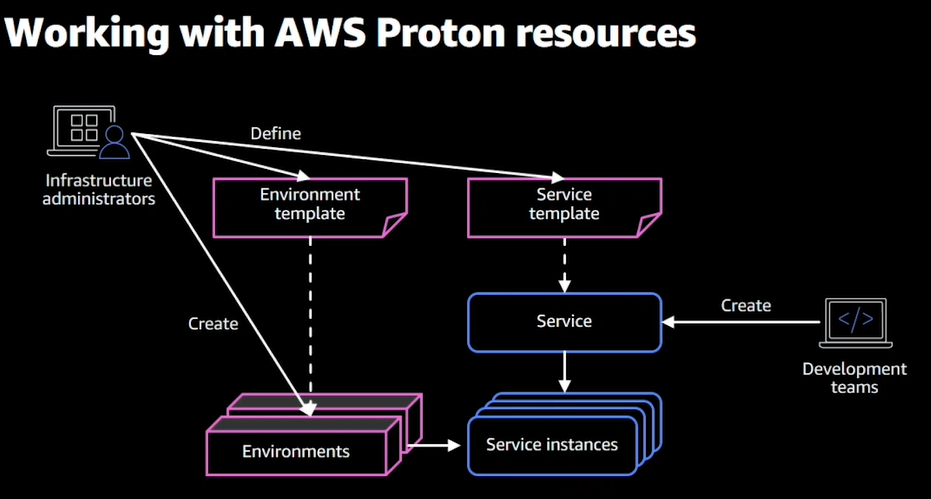
- Protonのコンセプト(Protonの主要なリソース)
- Environment:VPCやClusterを管理、サービスで共有するインフラ部分
- Services:ワークロードごとに設定、FaragateやLambdaなど

「 Proton使用時の流れ 」
- インフラのテンプレートを定義(Environment、Service)
- テンプレートからリソースをCreate
- アプリがサービスを選んでデプロイ(青枠)
- Protonのアーキテクチャ例
- 2のservice(Fargate、Lambda)と1つのEnvironment
- 環境はStagingとProduction2種類(今回の例では)
- Pipelineを使用して、Staging→Productionで展開できる(パイプラインが環境間で連携されている)

- Protonに定義を登録することで標準化できる
- 主にインフラ管理者向け

- Protonテンプレートの解剖(Anatomy)

- テンプレートの例
- 左側が環境ごとにテンプレートを分けた例
- 右側がProton、1つのテンプレートとSchemaを設定

- テンプレートができたらProtonの画面から登録
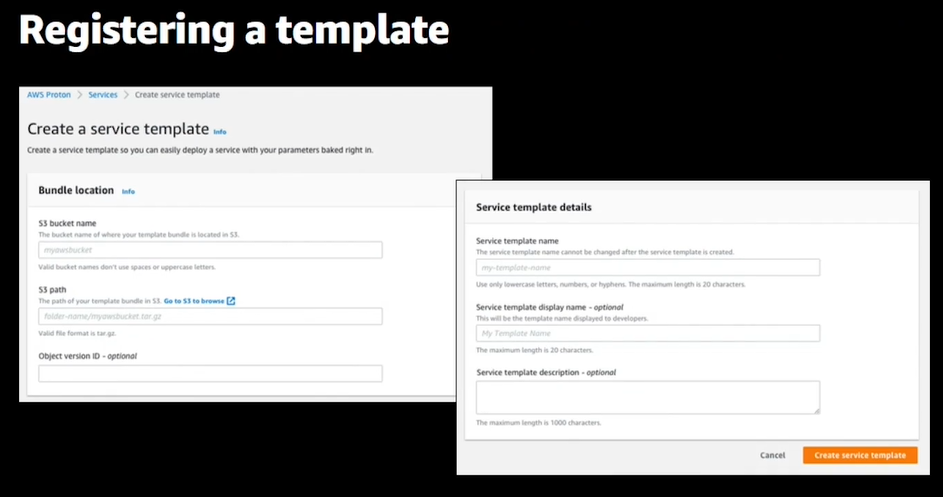
- 登録したテンプレートは画面上で管理できる
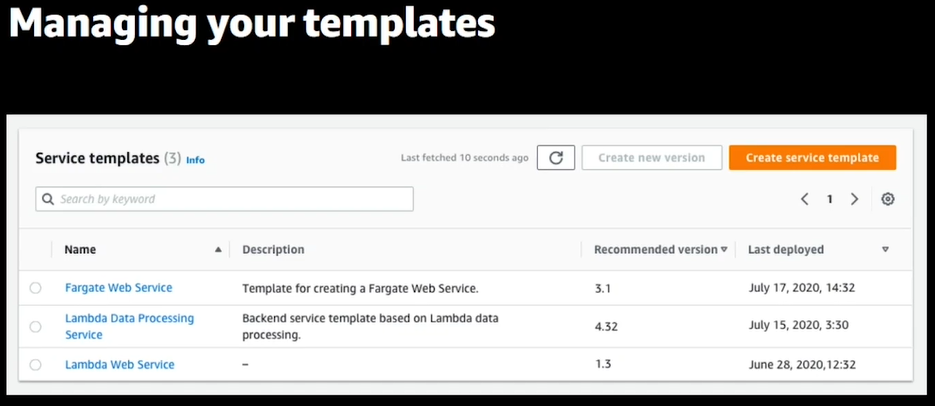
- サンプルテンプレートを多く公開しているので是非みてね!W-Aなテンプレートもあり

- テンプレートのバージョン管理
- 変更したらバージョン管理を
- マイナーとメジャーの2種類あり
- マイナーはDeveloper(アプリ)に影響を与えないインフラのアップデート
- メジャーはDeveloper(アプリ)に影響を与える構成変更のようなアップデート
- 基本は最新を使うようにしましょう

- テンプレートのバージョン管理画面
- 全バージョン詳細も見れる
- 現在どのテンプレートが使われているのかもわかる

- Environmentsで定義しているもの
- VPC、サブネット
- パイプラインとその中のステージ
- リソースプロビジョニングのためのIAMロール

- Developerはコードに集中
- コードを書いたらサービスを指定してデプロイ
- デプロイのサービスはマネージド化されて見える(?)

- 使用方法
1.サービステンプレートの選択

2.パラメータの入力、パラメータ項目はParameter Schemaで管理されている

3.サービスができたら画面上で確認できる
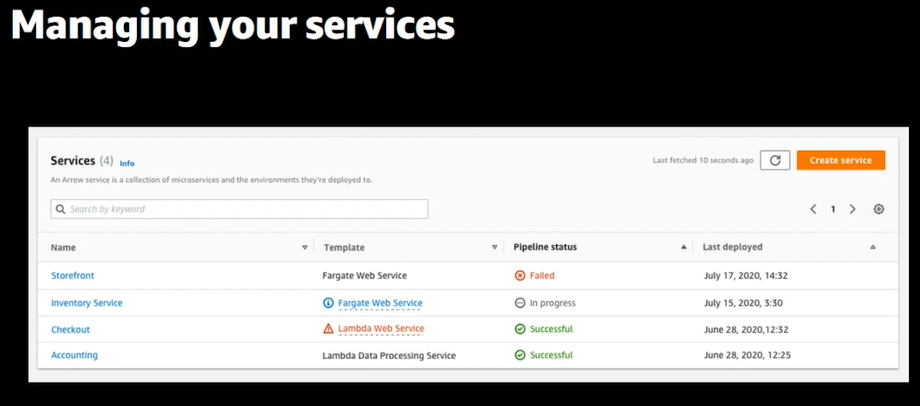
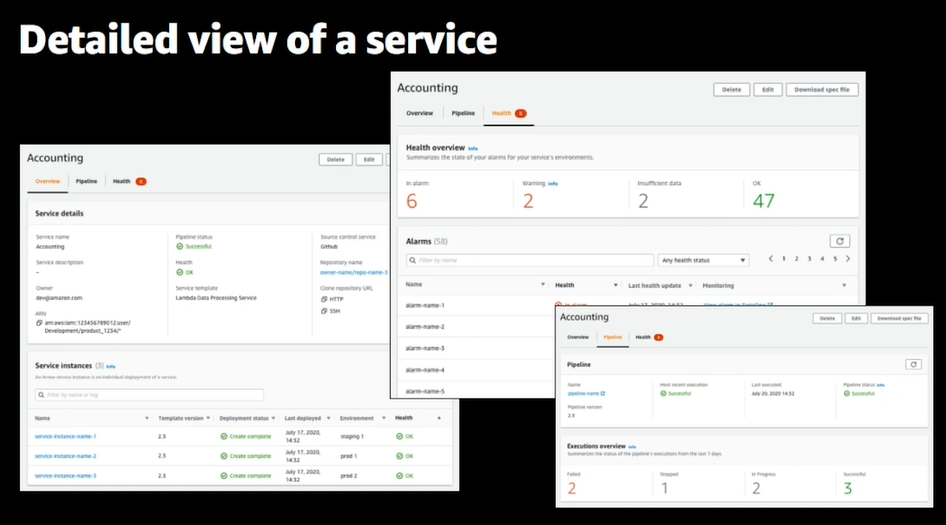
4.詳細も確認できる、パイプラインの状況やアラートの状況も見れる
まとめ
まだパブリックプレビュー、フィードバックください
- 今はCloudFormationが基本
- EnvironmentsとServiceのデプロイ、更新ができる
- CodePipelineとも連携
Roadmap(今後)

- 見てね!フィードバックもください(2回目)

私の感想、まとめ
英語で聞きながら書いているので少し間違っているところがあるかもしれません。すいません。何かあればご指摘ください。 ただProtonのコンセプトや方向性はこれで理解できたかなと思います。
背景を知るのは大事ですね、Protonの目的は以下のように感じました。
- インフラテンプレートの一元管理:色々なところで好き勝手に作るのではなく、ベストなものをProtonで集中管理。履歴管理もできる
- インフラ、アプリ(Developer)の役割明確化:Developerはコードに集中できるように。作ったコードをProton経由でデプロイすれば標準な形式でデプロイできる
- 各種リソースの状況管理:Protonを使用することで、どの環境でどのアプリ、テンプレートが使用されているのかわかるようになる
私の環境でもインフラテンプレートやパイプラインが多くなってきて、同様の課題を感じていたので、すばらしいサービスだと思います。 まだプレビュー段階なので、新機能にワクワクしながら実際の運用導入を検討したいと思います。